一个最小化的协程实现
背景
协程(coroutine)并不是一个新的概念
早期的计算机只有一个CPU核心,但是那时的操作系统和现在一样,并不是只能执行单一任务。当一个任务正在执行的时候,另一个任务来了,那么OS会根据优先级决定要不要切换到新的任务,如果需要的话,那么OS会保存当前任务的上下文,然后切换到另一个任务。
为什么现在还需要协程
我们知道,计算任务主要有两种分类:CPU密集型、I/O密集型。最早的服务器程序为了解决并发的问题会采用一个连接一个进程(如:Apache HTTP Server)。后来CPU发展到多核,这种架构演变为了一个连接一个线程,或者是预分配的线程池。再后来,操作系统有了事件循环的API,这种架构又演变成了EventLoop + Callback的方式,这个模式有很多变种,比如: loop per thread,但共同特点就是都是在回调函数中处理事件。随着软件规模的增长,回调的嵌套越来越严重,对编写和调试带来严重的负面影响。 后来,goroutine的出现又给这种架构带来了新的改变。以同步的方式编译异步的代码,直观,易阅读,易调试。最重要的是对一I/O密集型任务堪称绝配,因为协程的切换不需要操作系统参与,而且相比线程所需的内存空间更小,这就意味着,对于I/O密集型任务,同样的配置,使用协程比使用线程有着更优越的表现。
基础
为了实现一个最小化的协程(yield, resume),我们需要一些基础知识。
x64 assembly
现代的CPU都是64位的,即使还存在32位的操作系统,我们也选择不支持。如果一定要支持的话也不会有太大的改动。下面使用nasm语法编写几个实例:
列表求和:
section .data
list dq 1, 2, 3, 4, 5
len dq 5
section .text
global _start
_start:
mov rcx, [len]
mov rdi, 0
mov r8, 0
.loop:
add rdi, [list+r8*8]
inc r8
loop .loop
mov rax, 60
syscall
使用命令编译并运行:
╰─$ nasm -felf64 sum.asm
╭─abby@Chameleon ~/misc/asm
╰─$ ld sum.o
╭─abby@Chameleon ~/misc/asm
╰─$ ./a.out
╭─abby@Chameleon ~/misc/asm
╰─$ echo $?
15
列表排序: C语言实现主体
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef long long data_t;
extern void sort(data_t* , data_t);
int main(int argc, char* argv[])
{
if(argc < 2)
{
fprintf(stderr, "%s numbers\n", argv[0]);
return 1;
}
int len = argc - 1;
data_t* data = (data_t*)malloc(sizeof(data_t) * len);
memset(data, 0, sizeof(data_t)*len);
for(int i = 0; i < len; ++i)
{
data[i] = atoi(argv[i+1]);
}
sort(data, len);
for(int i = 0; i < len; ++i)
{
printf("%lld ", data[i]);
}
printf("\n");
free(data);
return 0;
}
汇编实现排序
section .text
global sort
sort:
mov r8, 0 ; index
.outter_loop:
mov r9, r8
jmp .inner_loop
.again:
inc r8
cmp r8, rsi
jne .outter_loop
xor rax, rax
ret
.inner_loop:
inc r9
cmp r9, rsi
je .again
mov rax, [rdi+r8*8]
cmp rax, [rdi+r9*8]
jge .swap
jmp .inner_loop
.swap:
mov rcx, [rdi+r9*8]
mov [rdi+r8*8], rcx
mov [rdi+r9*8], rax
jmp .inner_loop
编译,运行如下:
╭─abby@Chameleon ~/misc/asm
╰─$ nasm -felf64 sort.asm
╭─abby@Chameleon ~/misc/asm
╰─$ gcc sort_test.c sort.o
╭─abby@Chameleon ~/misc/asm
╰─$ ./a.out 3 1 -1 0 10 5
-1 0 1 3 5 10
calling convention
和名字一样,这只是一种约定,对于Linux来说,遵守的是System V的调用约定,即对于x64平台:rdi, rsi, rdx, rcx, r8, r9作为函数的前6个参数,其他的参数都压入栈中,函数如果使用: rbp, rbx, r12, r13, r14, r15这几个寄存器,这必须保证它们的值在函数调用过程中不发生改变(即,使用时通过push保存,使用后通过pop还原),rax、rdx作为返回值寄存器,寄存器的资源由调用者清理。
对于系统调用,调用的id必须存放在rax中,参数寄存器不变,如上面第一个实例中mov rax, 60表示系统调用为SYS_exit,而这个调用的参数则是rdi。
call frame layout
首先,有几个地方需要区分一下:
call 和 jmp 的区别
jmp直接跳转到指定地址call将返回地址压入栈中,再跳转到指定地址
push和pop与sub和add的区别
push将rsp减去某个数值,再将操作数复制到这个地址,pop将这个地址的内容复制到操作数,再将rsp增加某个数值sub将某个寄存器减去某个数值,add与sub相反
布局
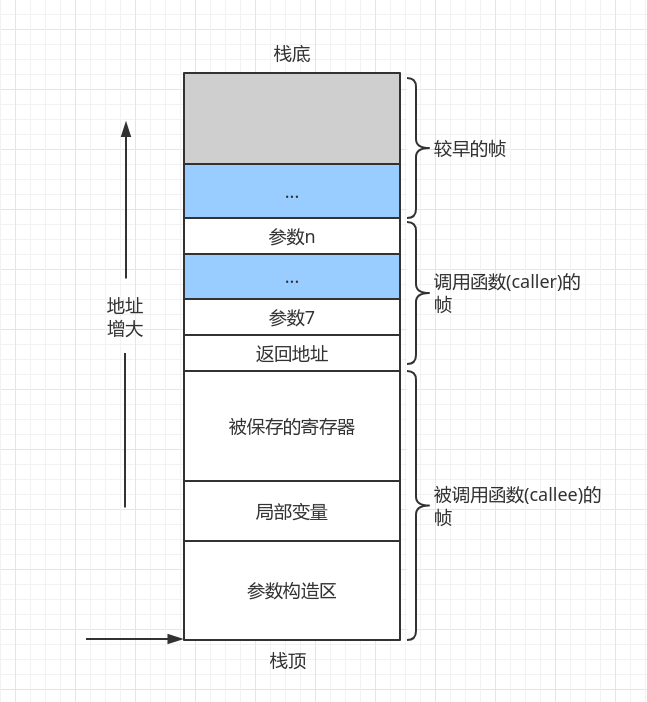
注意,x64没有提供操纵 rip寄存器的指令,改变rip只能通过call和跳转指令实现。图中返回值地址即rip存储的值。
实现 (stackful)
协程分两种:stackless和stackful。(asymmetric和symmetric不作讨论),下面实现的是有栈非对称协程。 要实现coroutine,我们需要做的就是模仿早期OS的行为,比如下面的例子:
void foo()
{
for(int i = 0; i < 10; ++i)
{
printf("i = %d\n",i);
yield();
}
}
int main()
{
foo();
for(int i = 0; i < 5; ++i) {
resume();
}
}
我们在调用foo()的时候,希望它立即返回,当我们调用resume()的时候,希望它回到foo()返回的地方继续执行。
也就是说,我们希望在执行foo()的时候,把它的上下文保存起来,然后立刻返回,在执行resume()时,把当前的上下文保存起来,然后跳转到foo()停止的地方继续执行,如此徃复。
那么首先要做的就是保存函数执行的上下文,其次,指定下一条指令的地址, 再者,恢复之前保存的上下文,最后跳转到下一条指令继续执行
保存上下文
这里的上下文指的是函数调用过程中使用到的寄存器和标志。需要保存哪些寄存器是因实现而异的,比如:
// #1
void switch_stack(void* old, void* new, int res);
与
// #2
void* switch_stack(void* new);
这两者需要保存的寄存器是不同的,因为它们的参数和返回值都不相同。下面以第#2种为例
push rbp
push rbx
push r15
push r14
push r13
push r12
简单的几个指令就将需要保存的寄存器保存了起来。
指定下一条指令的地址
对于#2,它的参数new是一块足够大的内存,这块内存上已经模仿前面的布局填充好了相应的数据,根据calling convention这块内存的布局必须是下面这样:
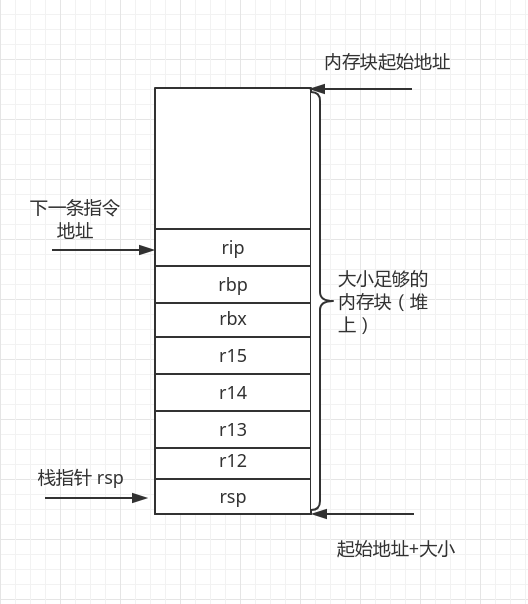 当我们把这样一块内存作为参数传入到
当我们把这样一块内存作为参数传入到#2中后,我们就需要将上下文变成新的上下文(原上下文已经保存)。
注意:这里的传入参数new按照上图所示,必须是rsp的地址。所以,替换上下文的操作是:
mov rax, rsp
mov rsp, rdi
第一句表示,我们需要将已经保存的上下文通过返回值返回出去,第二句表示替换当前的栈指针为我们“伪造”的“栈”(其实是堆上的内存)。
恢复上下文
这里的上下文指的是新传入的new中保存的上下文, 和前面保存上下文相反,我们可以使用pop来恢复
pop r12
pop r13
pop r14
pop r15
pop rbx
pop rbp
需要注意的是,pop的顺序必须和push的顺序相反,而单独的pop和push操作中的顺序是随意的,比如:
push r12
push r13
和
push r13
push r12
的效果是相同的。
跳转到指定地址
如上面一张内存布局图中所示,要跳转到指定的地址只需要
pop r8
mov rdi, rax
jmp r8
第一句表示,将rip的内容复制到r8中(这里可以指定任意没有使用的寄存器, 比如:rcx, r9等)。第二句表示,将上次保存的上下文作为下一条指令的第一个参数。最后一句表示跳转到这个地址继续执行。
完整示例及解释
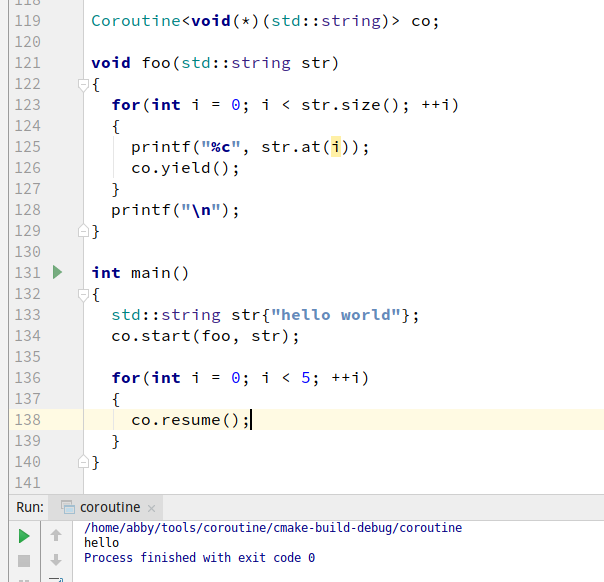 1, C++实现的
1, C++实现的Coroutine类(又一次使用了Inspector。。。)
2, 汇编实现的栈交换, 由于第一个和第三个参数在调用过程中没有改变,所以只需要关心第二个参数即可。 注意,这里的
mov r8, [rsp]
add rsp, 8
和
pop r8
是等价的, 参考前面提到的几个需要区分的地方。
源码已经上传到GitHub, 为了偷懒使用了C++14的 std::is_same_v和C++17的 std::apply,所以需要需要支持C++17的编译器,当然你也可以手动展开tuple支持低版本的编译器
展望
使用协程是当前服务端程序开发的趋势,可能正因为如此,C++标准委员会已经收到了很多proposal,目前看来,协程有希望在C++20或者C++23进入标准库(目前是在TS里面),另一方面,MSVC在2015版本就已经提供了协程的支持,后来clang也提供了协程的扩展支持。
参考和引用
- assembly64
- Calling convention
- CSAPP(3rd Edition) Figure 3-25
- coroutine