nvmf host 流程
NVMe over Fabrics IO 流程 (Linux-6.1.34 LTS)
设备管理
载入nvme-fabrics.ko后,驱动会在/dev目录下新建字符设备/dev/nvme-fabrics,这个设备用来和nvme命令交互,处理远程设备发现、删除和配置。
ctrlr初始化
fabrics.c:nvmf_dev_write
nvmf_create_ctrl
ops->create_ctrl (ops = nvme_rdma_transport)
rdma.c:nvme_rdma_create_ctrl
core.c:nvme_init_ctrl
rdma.c:nvme_rdma_setup_ctrl
nvme命令行将nvmf_dev_write所需的trtype、ip、nqn、kato等传入到/dev/nmve-fabrics,驱动调用对应transport设定的回调nvmf_dev_write
nvme_rdma_create_ctrl 这个函数复制创建ctrlr实体(nvme_rdma_ctrl是nvme_ctrl的容器),初始化重连、错误恢复已经reset这几个工作回调(work_struct),同时负责初始化nvme_ctrl创建字符设备文件(/dev/nvmeX)并初始化这个字符设备文件相关的操作函数表(nvme_ctrl_ops),随后启动nvme_ctrl
启动nvme_ctrl包括:配置io队列,设置ctrlr状态为LIVE,启动心跳检查和异步事件通知(AEN)。如果ctrlr不是 discovery ctrlr (queue_count == 1),还会开始以下任务:
- 扫描任务(scan_work用来获取namespace列表)
- 解除namespace中mq的暂停,还是处理IO请求
- 处理ANA (修改mpath状态)
注: nvmf_ctrl_options
这个结构中有一个成员 discovery_nqn用来区分是否是discovery ctrlr,代码如下
#define NVME_DISC_SUBSYS_NAME "nqn.2014-08.org.nvmexpress.discovery"
static int nvmf_parse_options(struct nvmf_ctrl_options *opts,
const char *buf)
{
...
case NVMF_OPT_NQN:
p = match_strdup(args);
if (!p) {
ret = -ENOMEM;
goto out;
}
kfree(opts->subsysnqn);
opts->subsysnqn = p;
nqnlen = strlen(opts->subsysnqn);
if (nqnlen >= NVMF_NQN_SIZE) {
pr_err("%s needs to be < %d bytes\n",
opts->subsysnqn, NVMF_NQN_SIZE);
ret = -EINVAL;
goto out;
}
opts->discovery_nqn =
!(strcmp(opts->subsysnqn,
NVME_DISC_SUBSYS_NAME));
...
}
namespace管理 (创建、删除)
namespace 即 /dev/nvmeXnY 这里的X表示ctrlr id、Y表示namespace id,(如果是多路径则是/dev/nvmeXcYnZ,X是subsystem id、Y是ctrlr id、Z是namespace id)负责将块层的请求通过transport传递到target
创建
nvme块设备(nvmeXnY or nvmeXcYnZ),在 nvme_scan_work (关联ctrl::scan_work)中创建
core.c:nvme_scan_work
nvme_clear_changed_ns_log
nvme_scan_ns_list
nvme_scan_ns_sequential
nvme_clear_changed_ns_log
处理AEN通知中的NS_CHANGED,这里仅仅是消耗AEN事件,然后就log丢弃,并没有使用log中的内容,而是直接往下走到nvme_scan_ns_list
nvme_scan_ns_list
通过管理队列(admin_q)向target请求可用的namespace数量nr_entries,每次取1024个namespace的id(以nvme_command::identify::nsid记录最新的nsid),target返回的nsid为0(SPDK中的实现是,编译subsystem中的namespace)
随后枚举nr_entries,向每一个可用的namespace发送NVME_ID_CNS_NS_DESC_LIST,根据返回结果对设备进行删除、更新
如果结果中设置了 nvme_ns_info::nvme_id_ns::nsattr = 1那么这个namespace将被设置为只读
如果host端没有找到对于的nsid,那么将会使用返回的nsinfo新建一个namespace
如果找到了,则会使用返回的nsinfo更新namespace,包括删除,设置容量大小,设置只读(特别的,如果CONFIG_NVME_MULTIPATH=y那么将设置多路径设备只读)
nvme_scan_ns_sequentail
如果前面的nvme_scan_ns_list失败,则会走到这个函数,这个函数通过管理队列向target请求namespace数量,在SPDK中,返回的是这个subsystem创建时设置的namespace数量(FE中设置的是16384),随后遍历这个nsid,向每一个nsid发送NVME_ID_CNS_NS_DESC_LIST,其余处理同nvme_scan_ns_list
这两个函数的区别是,nvme_scan_ns_list处理的都是active的namespace,而nvme_scan_ns_sequentail并不知道这个namespace在target的状态
nvme_mpath_alloc_disk
这个函数为多路径创建一个块设备nvmeXnY X表示subsystem id,Y表示多路径id,同时为这个设备设置块设备操作函数表nvme_ns_head_ops以及设置gendisk的private_data为自身(在open/submit_io时使用)
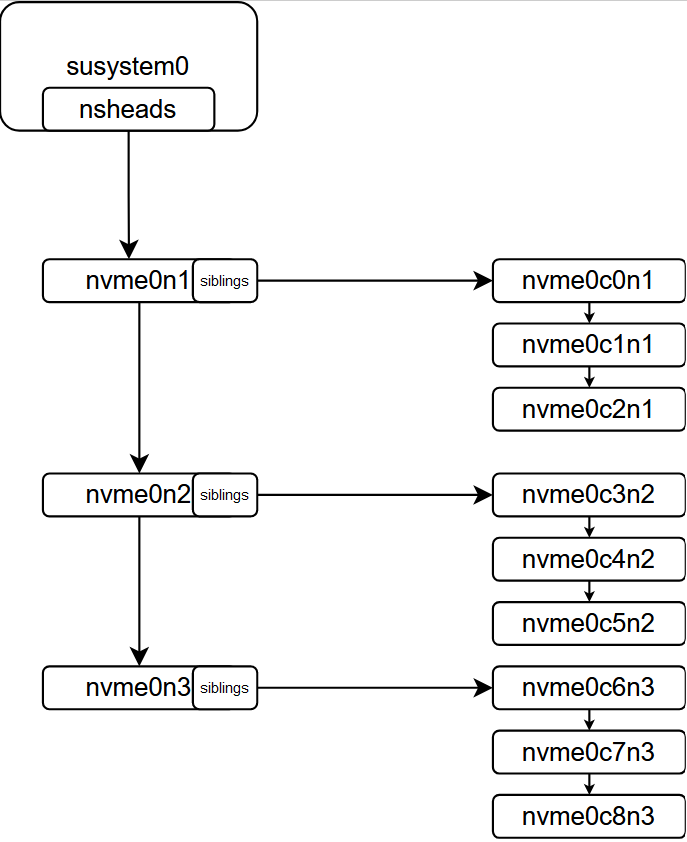
在函数 nvme_alloc_ns中会创建namespace实体,这个namespace会加入到ctrlr的namespaces链表中,同时,在多路径启用时,会为nvme_ns设置一个head,这个head就是聚合后的设备实体,具体流程是,根据nsid在ctrlr对应的subsystem中的nsheads链表中遍历,如果找到了,直接赋值给nvme_ns,如果没有找到,则创建一个nvme_ns_head并且加入到ctrlr->subsys->nsheads中,同时将nvme_ns加到nvme_ns_head->list中(通过nvme_ns::siblings串起来),结构大约是这样
删除
namespace的删除可能发生在
ctrlr 删除
AEN 请求删除
scan work中删除 删除namespace会删除掉
/dev/nvmeXnY(如果是多路径则是/dev/nvmeXcYnZ),步骤为设置namespace标准为
NVME_NS_REMOVING清除
NVME_NS_READY标准设置namespace容量为0
如果时多路径,则标准当前路径失效
删除掉
/dev/nvmeXnYor/dev/nvmeXcYnZ如果是多路径,并且是最后一条路径,则删除多路径设备
AEN (Asynchronous Event Notification) 和 ANA (Asymmetric Namespace Access)
当target端发送错误、状态变化时可以通过AEN通知host端进行相应处理,host端处理的入口是core.c:nvme_complete_async_event
主机驱动目前支持NOTICE和ERROR两种aer(Asynchronous Event Request)类型,前者主要用于通知namespace变化以及ANA变化,后者目前仅在aer子类型为 persistent internal error时重置(reset) ctrlr
对于NOTICE子类型的处理:
NS_CHANGED
设置ctrlr的events为NS_CHANGED,并触发ctrlr scan_work 对namespace进行创建、更新和删除
ANA(仅在CONFIG_NVME_MULTIPATH=y时生效)
收到这个子类型事件是,host开始启动 nvme_ana_work,除了这里,还有另外几处触发nvme_ana_work,分别是:
nvme_failover_reqnvme_mpath_add_disk
nvme_ana_work的作用是,读取target的ana log,然后使用读取到的nvme_ana_group_desc更新host端namespace的ana状态
需要注意的是,每当ana log中的nvme_ana_group_desc::state == NVME_ANA_CHANGE就会增加一个nr_change_groups,当nr_change_groups不为0时,host会更新定时器anatt_timer,这个定时器超时会导致ctrlr reset
IO 处理 (multipath)
当启用多路径时,真正的IO设备使用的是 nvmeXnY (X之subsystem id,Y指nvme_ns_head id),函数入口是nvme_ns_head_submit_bio,在创建nvme_ns_head时已经将nvme_ns_head设置到了块设备的private_data,因此虽然IO函数入口只有一个bio结构,也能找到对应的nvme_ns_head
在nvme_ns_head_submit_bio函数中,首先寻找合适的路径(nvme_ns),当找到路径时,设置bio的bi_bdev为找到路径的第一个分区,调用submit_bio_noacct 提交。如果没有找到就遍历这个nvme_ns_head上的所有路径,如果他们的ctrlr还在,那么暂存bio到head的重新请求队列中,打印错误:当前没有可用的路径。如果他们的ctrlr不再了,则直接提交IO error。
IO提交流程
初始化
nvme_alloc_ns
blk_mq_alloc_disk ctrlr->tagset->ops->queue_rq = nvme_rdma_queue_rq
__blk_mq_alloc_disk
blk_mq_init_queue_data
blk_mq_init_allocated_queue q->mq_ops = ctrl->tagset->ops
__alloc_disk_node
disk->part0 = bdev_alloc(disk, 0); // part0 has no fops, part0->bd_disk = nvme_ns::disk
disk->queue = q
提交IO
nvme_ns_head_submit_bio
nvme_find_path
bio_set_dev(bio, ns->disk->part0); bio->bi_bdev->bd_disk = nvme_ns::disk
submit_bio_noacct
submit_bio_noacct_nocheck
__submit_bio_noacct
__submit_bio
blk_mq_submit_bio
blk_add_rq_to_plug or blk_mq_try_issue_directly
__blk_mq_try_issue_directly
__blk_mq_issue_directly
q->mq_ops->queue_rq(hctx, &bd)
nvme_rdma_queue_rq
nvme_rdma_post_send -> to remote
IO 返回
blk_done_softirq
blk_complete_reqs
nvme_rdma_complete_rq
nvme_complete_rq => failover or retry or go ahead
blk_mq_end_request
__blk_mq_end_request
故障处理
故障可以分为IO本身故障和链路故障,IO本身故障的情况会启动重试,链路故障会导致切换链路,这里的IO指struct request
IO故障
当IO成功从target返回后,会进入 nvme_compele_rq函数,这里会检查nvme命令的状态
如果不是成功且重试次数没有到上限,则会进入重试流程,走到函数
nvme_retry_req,这里会增加nvme命令的重试次数,、同时会检查nvme命令是否设置了重试延迟,如果是则延迟重试如果重试次数到达上限,则完成这个命令,这个流程会将nvme状态码转为
blk_status_t
需要注意的是,IO故障不会触发重新选择路径,可能是使用用来的路径,也可能使用其他路径(当链路故障发生时)
链路故障
如果在nvme_complete_rq函数中检查当前命令状态为路径错误,则会标记这个命令的请求队列为dying随后进入nvme_failover_req
将
ns_head中当前失效路径标记为空,后续IO将不会选到这条路径如果当前命令的状态包含ana error,则重新读取ana log
将当前命令上的所有bio转移到
nvme_ns_head的requeue_list中,并重新调度request_work后续执行nvme_requeue_work,最后和新下发的IO走同一个流程nvme_ns_head_submit_io
在
nvme_requeue_work直接调用submit_bio_noacct这个函数最终会调到nvme_ns_head_submit_bio,因为在转移bio时设置的bio::bi_dev为nvme_ns_head::disk,因为当 bio->bi_dev->fops设设置了submit_io回调时会直接调用这个回调,在这里nvme_ns_head设置了fops为nvme_ns_head_ops